Spark Streaming基于kafka获取数据
2019.01.08
freeli
spark
热度
℃
Receiver方式
处理流程
实际上做kafka receiver的时候,通过receiver来获取数据,这个时候,kafka receiver是使用的kafka高层次的comsumer api来实现的。receiver会从kafka中获取数据,然后把它存储到我们具体的Executor内存中。然后Spark streaming也就是driver中,会根据这获取到的数据,启动job去处理。
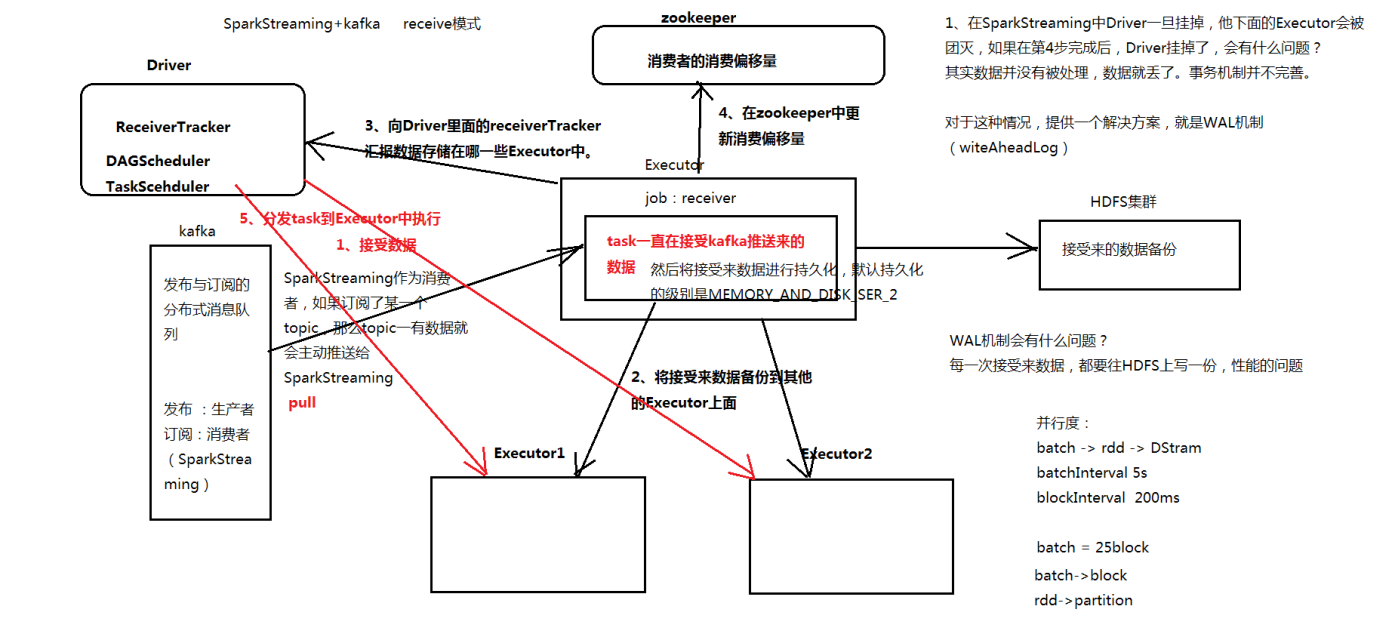
receiver缺点
- 已经拉取的数据消费失败后,会导致数据丢失。此问题虽然可以通过WAL方式或者Memory_and_Disc2解决,但是存在耗时等问题
- 使用了kafka consumer的高阶API,KafkaInputDStream的实现和我们常用的consumer实现类似,需要zk额外的记录偏移量
Direct方式
实现
在使用kafka接收消息时,都是调用了KafkaUtils里面createStream的不同实现。
receiver方式的实现方式如下。
def createStream(
ssc: StreamingContext,
zkQuorum: String,
groupId: String,
topics: Map[String, Int],
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[(String, String)] = {
val kafkaParams = Map[String, String](
"zookeeper.connect" -> zkQuorum, "group.id" -> groupId,
"zookeeper.connection.timeout.ms" -> "10000")
val walEnabled = WriteAheadLogUtils.enableReceiverLog(ssc.conf)
new KafkaInputDStream[K, V, U, T](
ssc, kafkaParams, topics, walEnabled, storageLevel)
}
|
direct方式实现消费
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]: ClassTag,
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)] = {
val messageHandler = (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message)
val kc = new KafkaCluster(kafkaParams)
val fromOffsets = getFromOffsets(kc, kafkaParams, topics)
new DirectKafkaInputDStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, fromOffsets, messageHandler)
}
|
特点
- Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
- 由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。而Receiver的方式则不能保证,因为Receiver和ZK中的数据可能不同步,Spark Streaming可能会重复消费数据。而Direct api直接是操作kafka的,spark streaming自己负责追踪消费这个数据的偏移量或者offset,并且自己保存到checkpoint,所以它的数据一定是同步的,一定不会被重复。
- 底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据,这个时候,Direct Api访问kafka带来的一个显而易见的性能上的好处就是,如果你要读取多个partition,Spark也会创建RDD的partition,这个时候RDD的partition和kafka的partition是一致的。所以增加kafka中的topic的partition数量可以提高并行度。
- 偏移量:默认从最新偏移量(
largest)开始消费。如果设置了auto.offset.reset参数值为smallest将从最小偏移处开始消费。
checkpoint恢复后,如果数据累积太多处理不过来,怎么办?
1)限速,通过spark.streaming.kafka.maxRatePerPartition参数配置
2)增强机器的处理能力
3)放到数据缓冲池中。
模式比对
- .简化并行性:无需创建多个输入Kafka流并且结合它们。 使用directStream,Spark Streaming将创建与要消费的Kafkatopic中partition分区一样多的RDD分区,这将从Kafka并行读取数据。 因此,在Kafka和RDD分区之间存在一对一映射,这更容易理解和调整。
- 效率:在第一种方法中实现零数据丢失需要将数据存储在预写日志中,该日志进一步复制数据。 这实际上是低效的,因为数据有效地被复制两次 - 一次是Kafka,另一次是写入提前日志。 第二种方法消除了问题,因为没有接收器(zookeeper),因此不需要预写日志。 将元数据信息直接保存在kafka中,可以从Kafka恢复消息。
- Exactly-once语义:第一种方法使用Kafka的高级API在Zookeeper中存储消耗的偏移量。这是传统上消费Kafka数据的方式。虽然这种方法(与预写日志结合)可以确保零数据丢失(即至少一次语义),但是一些记录在一些故障下可能被消耗两次。这是因为Spark Streaming可靠接收的数据与Zookeeper跟踪的偏移之间存在不一致。因此,在第二种方法中,我们使用简单的Kafka API,不使用Zookeeper的。偏移由Spark Streaming在其检查点内跟踪。这消除了Spark Streaming和Zookeeper / Kafka之间的不一致,所以每个记录被Spark Streaming有效地精确接收一次,尽管失败了。为了实现输出结果的一次性语义,将数据保存到外部数据存储的输出操作必须是幂等的,或者是保存结果和偏移量的原子事务。
direct源码
获取offset集合,然后创建DirectKafkaInputDStream对象
private[kafka] def getFromOffsets(
kc: KafkaCluster,
kafkaParams: Map[String, String],
topics: Set[String]
): Map[TopicAndPartition, Long] = {
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase(Locale.ROOT))
val result = for {
topicPartitions <- kc.getPartitions(topics).right
leaderOffsets <- (if (reset == Some("smallest")) {
kc.getEarliestLeaderOffsets(topicPartitions)
} else {
kc.getLatestLeaderOffsets(topicPartitions)
}).right
} yield {
leaderOffsets.map { case (tp, lo) =>
(tp, lo.offset)
}
}
KafkaCluster.checkErrors(result)
}
def createDirectStream{
new DirectKafkaInputDStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, fromOffsets, messageHandler)
}
|
DirectKafkaInputDStream.compute中创建KafkaRDD,并将offsets信息发送给inputStreamTracker.
override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = {
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
val rdd = KafkaRDD[K, V, U, T, R](
context.sparkContext, kafkaParams, currentOffsets, untilOffsets, messageHandler)
val offsetRanges = currentOffsets.map { case (tp, fo) =>
val uo = untilOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo.offset)
}
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
currentOffsets = untilOffsets.map(kv => kv._1 -> kv._2.offset)
Some(rdd)
}
|
KafkaRDD计算时直接从kafka上拉取数据
override def compute(thePart: Partition, context: TaskContext): Iterator[R] = {
val part = thePart.asInstanceOf[KafkaRDDPartition]
new KafkaRDDIterator(part, context)
}
private class KafkaRDDIterator(
part: KafkaRDDPartition,
context: TaskContext) extends NextIterator[R] {
val kc = new KafkaCluster(kafkaParams)
var requestOffset = part.fromOffset
var iter: Iterator[MessageAndOffset] = null
val consumer:SimpleConsumer = {
if (context.attemptNumber > 0) {
kc.connectLeader(part.topic, part.partition).fold(
errs => throw new SparkException(
s"Couldn't connect to leader for topic ${part.topic} ${part.partition}: " +
errs.mkString("\n")),
consumer => consumer
)
} else {
kc.connect(part.host, part.port)
}
}
private def fetchBatch: Iterator[MessageAndOffset] = {
val req = new FetchRequestBuilder()
.addFetch(part.topic, part.partition, requestOffset, kc.config.fetchMessageMaxBytes)
.build()
val resp = consumer.fetch(req)
handleFetchErr(resp)
resp.messageSet(part.topic, part.partition)
.iterator
.dropWhile(_.offset < requestOffset)
}
private def handleFetchErr(resp: FetchResponse) {
if (resp.hasError) {
throw ErrorMapping.exceptionFor(err)
}
}
override def getNext(): R = {
if (iter == null || !iter.hasNext) {
iter = fetchBatch
}
if (!iter.hasNext) {
assert(requestOffset == part.untilOffset, errRanOutBeforeEnd(part))
finished = true
null.asInstanceOf[R]
} else {
val item = iter.next()
if (item.offset >= part.untilOffset) {
finished = true
null.asInstanceOf[R]
} else {
requestOffset = item.nextOffset
messageHandler(new MessageAndMetadata(
part.topic, part.partition, item.message, item.offset, keyDecoder, valueDecoder))
}
}
}
}
}
|
通过chekpoint的方式保存offset
class DirectKafkaInputDStream extends InputDStream{
override val checkpointData =new DirectKafkaInputDStreamCheckpointData
}
class DirectKafkaInputDStreamCheckpointData extends DStreamCheckpointData(this) {
def batchForTime: mutable.HashMap[Time, Array[(String, Int, Long, Long)]] = {
data.asInstanceOf[mutable.HashMap[Time, Array[OffsetRange.OffsetRangeTuple]]]
}
}
|

