此文是从思维导图中导出稍作调整后生成的,思维脑图对代码浏览支持不是很好,为了更好阅读体验,文中涉及到的源码都是删除掉不必要的代码后的伪代码,如需获取更好阅读体验可下载脑图配合阅读:
此博文共分为四个部分:




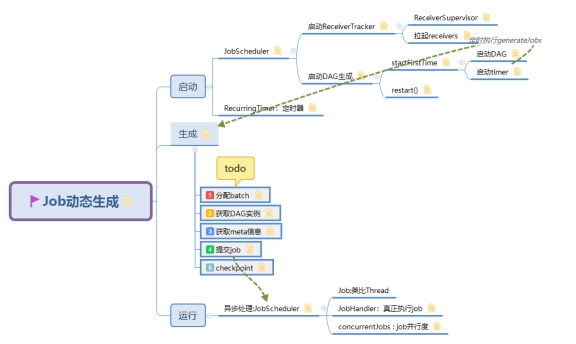
在 Spark Streaming 程序的入口,我们都会定义一个 batchDuration,就是需要每隔多长时间就比照静态的 DStreamGraph 来动态生成一个 RDD DAG 实例。在 Spark Streaming 里,总体负责动态作业调度的具体类是 JobScheduler。
JobScheduler 有两个非常重要的成员:JobGenerator 和 ReceiverTracker。JobScheduler 将每个 batch 的 RDD DAG 具体生成工作委托给 JobGenerator,而将源头输入数据的记录工作委托给 ReceiverTracker。
1. 启动
1.1. JobScheduler
job运行的总指挥是JobScheduler.start(),
JobScheduler 有两个非常重要的成员:JobGenerator 和 ReceiverTracker。JobScheduler 将每个 batch 的 RDD DAG 具体生成工作委托给 JobGenerator,而将源头输入数据的记录工作委托给 ReceiverTracker。
在StreamingContext中启动scheduler
class StreamingContext(sc,cp,batchDur){ |
在JobScheduler中启动recieverTracker和JobGenerator
class JobScheduler(ssc) { |
1.1.1. 启动ReceiverTracker
在JobScheduler的start中启动ReceiverTraker:
receiverTracker.start():RecieverTracker 调用launchReceivers方法
class ReceiverTracker { |
1.1.1.1. ReceiverSupervisor
ReceiverTracker将RDD DAG和启动receiver的Func包装成ReceiverSupervisor发送到最优的Excutor节点上
1.1.1.2. 拉起receivers
从ReceiverInputDStreams中获取Receivers,并把他们发送到所有的worker nodes:
class ReceiverTracker { |
1.1.2. 启动DAG生成
在JobScheduler的start中启动JobGenerator:JobGenerator.start()
1.1.2.1. startFirstTime
首次启动
private def startFirstTime() { |
1.1.2.1.1. 启动DAG
graph的生成是在StreamingContext中:
val graph: DStreamGraph={ |
在GenerateJobs中启动graph:
graph.start(nowTime-batchDuration) |
1.1.2.1.2. 启动timer
JobGenerator中定义了一个定时器:
val timer=new RecurringTimer(colck,batchDuaraion, |
在JobGenerator启动时会开始执行这个调度器:
timer.start(startTime.milliseconds) |
1.2. RecurringTimer:定时器
// 来自 JobGenerator
private[streaming] |
通过代码也可以看到,整个 timer 的调度周期就是 batchDuration,每次调度起来就是做一个非常简单的工作:往 eventLoop 里发送一个消息 —— 该为当前 batch (new Time(longTime)) GenerateJobs 了!
2. 生成

JobGenerator中定义了一个定时器,在定时器中启动生成job操作
class JobGenerator: |
2.2. 获取DAG实例
在生成Job并提交到excutor的第二步,
JobGenerator->DStreamGraph->OutputStreams->ForEachDStream->TransformationDStream->InputDStream
具体流程是:
- 1. JobGenerator调用了DStreamGraph里面的gererateJobs(time)方法
- 2. DStreamGraph里的generateJobs方法遍历了outputStreams
- 3. OutputStreams调用了其generateJob(time)方法
- 4. ForEachDStream实现了generateJob方法,调用了:
parent.getOrCompute(time)
递归的调用父类的getOrCompute方法去动态生成物理DAG图
3. 运行
3.1. 异步处理:JobScheduler
JobScheduler通过线程池执行从JobGenerator提交过来的Job,jobExecutor异步的去处理提交的job
class JobScheduler{ |
3.1.1. Job:类比Thread
3.1.2. JobHandler:真正执行job
JobHandler 除了做一些状态记录外,最主要的就是调用 job.run(),
在 ForEachDStream.generateJob(time) 时,是定义了 Job 的运行逻辑,即定义了 Job.func。而在 JobHandler 这里,是真正调用了 Job.run()、将触发 Job.func 的真正执行!
// 来自 JobHandler |
3.1.3. concurrentJobs : job并行度
spark.streaming.concurrentJobs job并行度
这里 jobExecutor 的线程池大小,是由 spark.streaming.concurrentJobs 参数来控制的,当没有显式设置时,其取值为 1。
进一步说,这里 jobExecutor 的线程池大小,就是能够并行执行的 Job 数。而回想前文讲解的 DStreamGraph.generateJobs(time) 过程,一次 batch 产生一个 Seq[Job},里面可能包含多个 Job —— 所以,确切的,有几个 output 操作,就调用几次 ForEachDStream.generatorJob(time),就产生出几个 Job
脑图制作参考:https://github.com/lw-lin/CoolplaySpark
完整脑图链接地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png

