此文是从思维导图中导出稍作调整后生成的,思维脑图对代码浏览支持不是很好,为了更好阅读体验,文中涉及到的源码都是删除掉不必要的代码后的伪代码,如需获取更好阅读体验可下载脑图配合阅读:
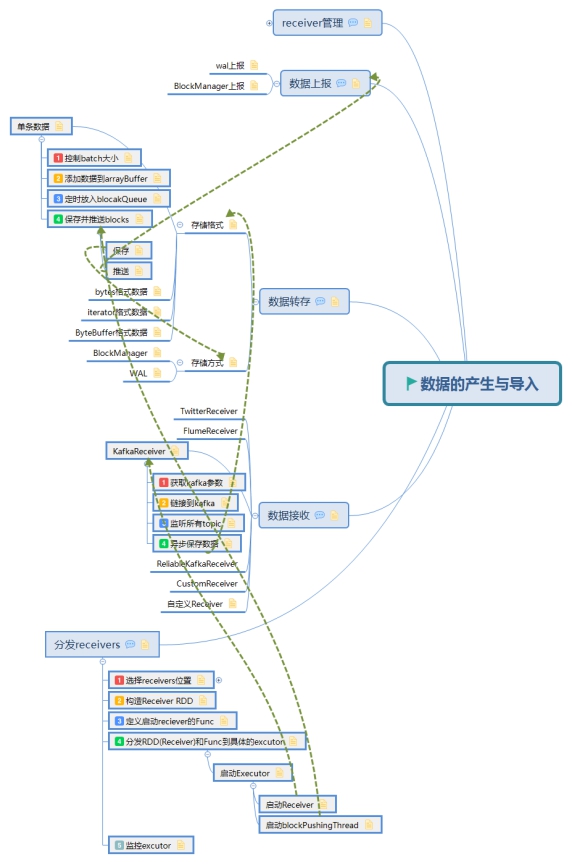
此博文共分为四个部分:
DAG定义 Job动态生成 数据的产生与导入 容错
数据的产生与导入主要分为以下五个部分
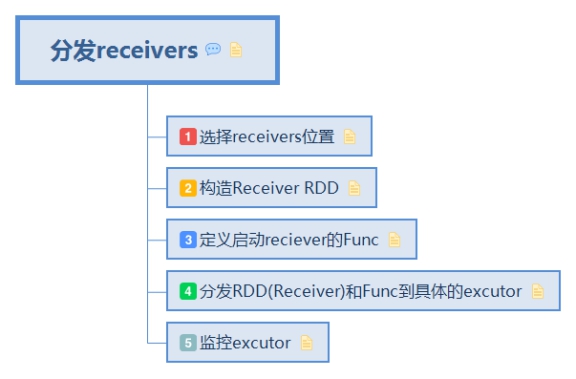
1. 分发receivers 由 Receiver 的总指挥 ReceiverTracker 分发多个 job(每个 job 有 1 个 task),到多个 executor 上分别启动 ReceiverSupervisor 实例
从ReceiverInputDStreams中获取Receivers,并把他们发送到所有的worker nodes:
class ReceiverTracker var endpoint:RpcEndpointRef = private def **launchReceivers** val receivers=inputStreams.map{nis=> val rcvr=nis.getReceiver() rcvr } endpoint.send(StartAllReceivers (receivers)) } }
1.1. 选择receivers位置
目的地选择分两种情况:初始化选择和失败重启选择
class ReceiverTracker val schedulingPolicy= new ReceiverSchedulingPolicy () def receive case StartAllReceivers (receivers) => ... case RestartReceiver (receiver)=> ... } }
1.1.1. 首次启动 1. 选择最优executors位置
2. 遍历构造最终分发的excutor
class ReceiverTracker val schedulingPolicy= new ReceiverSchedulingPolicy () def receive case StartAllReceivers (receivers) => val locations= schedulingPolicy.scheduleReceivers( receivers,getExecutors ) for (receiver<- receivers){ val executors = scheduledLocations( receiver.streamId) startReceiver(receiver, executors) } case RestartReceiver (receiver)=> ... } }
1.1.2. 失败重启 1.获取之前的executors
2. 计算新的excutor位置
2.1 之前excutors可用,则使用之前的
2.2 之前的不可用则重新计算位置
3. 发送给worker重启receiver
class ReceiverTracker val schedulingPolicy= new ReceiverSchedulingPolicy () def receive case StartAllReceivers (receivers) => ... case RestartReceiver (receiver)=> val oldScheduledExecutors =getStoredScheduledExecutors( receiver.streamId ) val scheduledLocations = if (oldScheduledExecutors.nonEmpty) { oldScheduledExecutors } else { schedulingPolicy.rescheduleReceiver() startReceiver( receiver, scheduledLocations) } }
1.1.3. 选择策略 策略选择由ReceiverSchedulingPolicy实现,默认策略是轮训(round-robin),在1.5版本之前是使用依赖 Spark Core 的 TaskScheduler 进行通用分发,
在1.5之前存在executor分发不均衡问题导致Job执行失败:
如果某个 Task 失败超过 spark.task.maxFailures(默认=4) 次的话,整个 Job 就会失败。这个在长时运行的 Spark Streaming 程序里,Executor 多失效几次就有可能导致 Task 失败达到上限次数了,如果某个 Task 失效一下,Spark Core 的 TaskScheduler 会将其重新部署到另一个 executor 上去重跑。但这里的问题在于,负责重跑的 executor 可能是在下发重跑的那一刻是正在执行 Task 数较少的,但不一定能够将 Receiver 分布的最均衡的。
策略代码:
val scheduledLocations =ReceiverSchedulingPolicy .scheduleReceivers(receivers,xecutors)val scheduledLocations =ReceiverSchedulingPolicy .rescheduleReceiver(receiver, ...)
1.2. 构造Receiver RDD 将receiver列表转换为RDD
class ReceiverTracker def receive ... startReceiver(receiver, executors) } def startReceiver receiver: Receiver [_], scheduledLocations: Seq [TaskLocation ]){ } } class ReceiverTracker def startReceiver ... val receiverRDD: RDD [Receiver ] = if (scheduledLocations.isEmpty) { **ssc.sc.makeRDD(Seq (receiver), 1 )** } else { val preferredLocations = scheduledLocations.map(_.toString).distinct ssc.sc.makeRDD(Seq (receiver -> preferredLocations)) } receiverRDD.setName(s" $receiverId " ) ... } }
1.3. 定义启动reciever的Func 将每个receiver,spark环境变量,hadoop配置文件,检查点路径等信息传送给excutor的接收对象ReceiverSupervisorImpl
class ReceiverTracker def startReceiver ... val startReceiverFunc: Iterator [Receiver [_]]=>Unit = (iterator:Iterator )=>{ val receiver=iterator.next() val supervisor= new ReceiverSupervisoImpl ( receiver, SparkEnv , HadoopConf , checkpointDir, ) supervisor.start(), supervisor.awaitTermination() } ... }
1.4. 分发RDD(Receiver)和Func到具体的excutor
将前两部定义的rdd和fun从driver提交到excutor
class ReceiverTracker def startReceiver ... val future=ssc.sparkContext.submitJob( receiverRDD, startReceverFunc, ) ... } }
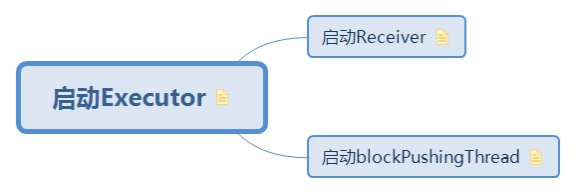
1.4.1. 启动Executor
Executor的启动在Receiver类中定义,在ReceiverSupervisor类中调用,在Receiver的子类中实现
excutor中共需要启动两个线程
-1. 启动Receiver接收数据
- 2. 启动pushingThread定时推送数据到driver
class ReceiverSupervisor ( receiver: Receiver , conf: sparkConf def start onStart() startReceiver() } }
1.4.1.1. 启动Receiver 启动Receiver,开始接收数据
class ReceiverSupervisor ( receiver: Receiver , conf: sparkConf def start onStart() startReceiver() } def startReceiver receiverState=Started receiver.onStart() } }
1.4.1.2. 启动blockPushingThread 启动pushTread,定时推送信息到driver
class ReceiverSupervisor ( receiver: Receiver , conf: sparkConf def start onStart() startReceiver() } def startReceiver receiverState=Started receiver.onStart() } } def onStart registeredBlockGenerators.asScala.foreach { _.start() } } } class BlockGenerator def start blockIntervalTimer.start() blockPushingThread.start() } }
1.5. 监控excutor 启动 Receiver 实例,并一直 block 住当前线程
在1.5版本之前,一个job包含多个task,一个task失败次数失败超过4次后,整个Job都会失败,1.5版本之后一个job只包含一个task,并且添加了可重试机制 ,大大增加了job的活性
Spark Core 的 Task 下发时只会参考并大部分时候尊重 Spark Streaming 设置的 preferredLocation 目的地信息,还是有一定可能该分发 Receiver 的 Job 并没有在我们想要调度的 executor 上运行。此时,在第 1 次执行 Task 时,会首先向 ReceiverTracker 发送 RegisterReceiver 消息,只有得到肯定的答复时,才真正启动 Receiver,否则就继续做一个空操作,导致本 Job 的状态是成功执行已完成。当然,ReceiverTracker 也会另外调起一个 Job,来继续尝试 Receiver 分发……如此直到成功为止。
一个 Receiver 的分发 Job 是有可能没有完成分发 Receiver 的目的的,所以 ReceiverTracker 会继续再起一个 Job 来尝试 Receiver 分发。这个机制保证了,如果一次 Receiver 如果没有抵达预先计算好的 executor,就有机会再次进行分发,从而实现在 Spark Streaming 层面对 Receiver 所在位置更好的控制。
对 Receiver 的监控重启机制
上面分析了每个 Receiver 都有专门的 Job 来保证分发后,我们发现这样一来,Receiver 的失效重启就不受 spark.task.maxFailures(默认=4) 次的限制了。
因为现在的 Receiver 重试不是在 Task 级别,而是在 Job 级别;并且 Receiver 失效后并不会导致前一次 Job 失败,而是前一次 Job 成功、并新起一个 Job 再次进行分发。这样一来,不管 Spark Streaming 运行多长时间,Receiver 总是保持活性的,不会随着 executor 的丢失而导致 Receiver 死去。
// todo 阻塞,知道executor返回发送结果
class ReceiverTracker def startReceiver ... future.onComplete { case Success (_)=> ... case Failure ())=> onReceiverJobFinish(receiverId) ... }}(ThreadUtils .sameThread) ... }
2. 数据接收 每个 ReceiverSupervisor 启动后将马上生成一个用户提供的 Receiver 实现的实例 —— 该 Receiver 实现可以持续产生或者持续接收系统外数据,比如 TwitterReceiver 可以实时爬取 twitter 数据 —— 并在 Receiver 实例生成后调用 Receiver.onStart()。
数据的接收由Executor端的Receiver实现,启动和停止需要子类实现,存储基类实现,供子类调用
abstract class Receiver [T ](val storageLevel: StorageLevel ) extends Serializable def onStart def onStop def store T ) {...} def store ArrayBuffer [T ]) {...} def store Iterator [T ]) {...} def store ByteBuffer ) {...} ... }
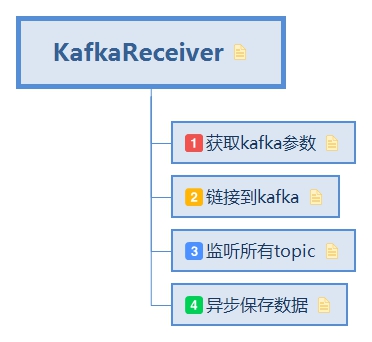
通过kafka去接收数据,
class KafkaInputDStream **extends Receiver** ( _ssc : StreamingContext , kafkaParams : Map [String ,String ], topics : Map [String ,Int ], useReliableReceiver : Boolean storageLevel : StorageLevel def onStart } }
2.3.1. 获取kafka参数 拼接kafka consumer所需参数
class KafkaInputDStream ( def onStart ** val props=new Properties () kafkaParams.foreach( p=>props.put(p._1,p._2) ) } }
2.3.2. 链接到kafka class KafkaInputDStream ( var consumerConnector:ConsumerConnector def onStart val props=new Properties () kafkaParams.foreach( p=>props.put(p._1,p._2) ) val consumerConf= new ConsumerConfig (props) consumerConnector= Consumer .create(consumerConf) } }
2.3.3. 监听所有topic class KafkaInputDStream ( var consumerConnector:ConsumerConnector def onStart val props=new Properties () kafkaParams.foreach( p=>props.put(p._1,p._2) ) val consumerConf= new ConsumerConfig (props) consumerConnector= Consumer .create(consumerConf) val topicMessageStreams= consumerConnector.createMessage() val executorPool=ThreadUtils . newDaemonFixedTreadPool( topics.values.sum, "kafkaMessageHandler" ) topicMessageStreams.values.foreach( streams=>streams.foreach{ stream=> executorPool.submit( new MessageHandler (stream) ) } ) } }
2.3.4. 异步保存数据 class KafkaInputDStream ( var consumerConnector:ConsumerConnector def onStart val props=new Properties () kafkaParams.foreach( p=>props.put(p._1,p._2) ) val consumerConf= new ConsumerConfig (props) consumerConnector= Consumer .create(consumerConf) val topicMessageStreams= consumerConnector.createMessage() val executorPool=ThreadUtils . newDaemonFixedTreadPool( topics.values.sum, "kafkaMessageHandler" ) topicMessageStreams.values.foreach( streams=>streams.foreach{ stream=> executorPool.submit( new MessageHandler (stream) ) } ) } class MessageHandler ( stream:KafkaStream [K ,V ] ) extends Runable def run val streamIterator=stream.iterator() while (streamIterator.hasNext()){ val msgAndMetadata= streamIterator.next() **store(** **msgAndMetadata.key,** **msgAndMetadata.message** **)** } } } } }
自定义的Receiver只需要继承Receiver类,并实现onStart方法里新拉起数据接收线程,并在接收到数据时 store() 到 Spark Streamimg 框架就可以了。
3. 数据转存 Receiver 在 onStart() 启动后,就将持续不断地接收外界数据,并持续交给 ReceiverSupervisor 进行数据转储
3.1. 存储格式
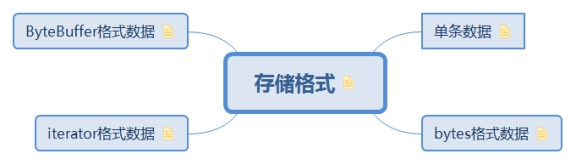
Receiver在调用store方法后,根据不同的入参会调用ReceiverSupervisor的不同方法。ReceiverSupervisor的方法由ReceiverSupervisorImpl实现
class Receiver var supervisor:ReceiverSupervisor ; def strore T ){ supervisor.pushSigle(dataItem) } def store ByteBuffer ){ supervisor.pushBytes(bytes,None ,None ) } def store Iterator [T ]){ supervisor.pusthIteratro(dataIterator) } def store ArrayBuffer [T ]){ supervisor.pushArrayBuffer(dataBuffer) } }
3.1.1. 单条数据
调用ReceiverSupervisorImpl的pushSigle方法保存单条数据
class ReceiverSupervisorImpl val defaultBlockGenerator= new BlockGenerator ( blockGeneratorListener, streamId, env.conf ) def pushSinge Any ){ defaultBlockGenerator.addData(data) } }
3.1.1.1. 控制batch大小 先检查接收数据的频率,控制住频率就控制了每个batch需要处理的最大数据量
就是在加入 currentBuffer 数组时会先由 rateLimiter 检查一下速率,是否加入的频率已经太高。如果太高的话,就需要 block 住,等到下一秒再开始添加。这里的最高频率是由 spark.streaming.receiver.maxRate (default = Long.MaxValue) 控制的,是单个 Receiver 每秒钟允许添加的条数。控制了这个速率,就控制了整个 Spark Streaming 系统每个 batch 需要处理的最大数据量。
class BlockGenerator def addData Any )={ waitToPush() } } class RateLimiter (conf:SparkConf ) val maxRateLimit= conf.getLong( "spark.streaming.receiver.maxRate" , Long .MaxValue ) val rateLimiter=GuavaRateLimiter .create( maxRateLimit.toDouble ) def waitToPush rateLimiter.acquire() } }
3.1.1.2. 添加数据到arrayBuffer 如果频率正常,则把数据添加到数组中,否则抛异常
class BlockGenerator var currentBuffer=new ArrayBuffer [Any ] def addData Any )={ waitToPush() synchronized{ if (state==Active ){ currentBuffer+=data }else { throw new SparkException { "connot add data ..." } } } } }
3.1.1.3. 定时放入blocakQueue 3.1 清空currentBuffer
3.2 将block块放入blocakQueue
class BlockGenerator var currentBuffer=new ArrayBuffer [Any ] val blockIntervalTimer= new RecurringTimer ( clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator" ) val queueSize=conf.getInt( "spark.streaming.blockQueueSize" ,10 ) val blocksForPushing= new ArrayBlockingQueue [Block ](queueSize) def addData Any )={ waitToPush() synchronized{ currentBuffer+=data } def updateCurrentBuffer Long ){ var newBlock:Block =null synchronized{ val newBlockBuffer=currentBuffer currentBuffer=new ArrayBuffer [Any ] newBlock= new Block (id,newBlockBuffer) blocksForPushing.put(newBlock) } } } }
3.1.1.4. 保存并推送blocks
在初始化BlockGenerator时,启动一个线程去持续的执行pushBlocks方法。如果还没有生成blocks,则阻塞调用queue.poll去获取数据,如果已经存在blocks块,则直接queue.take(10)
class BlockGenerator var currentBuffer=new ArrayBuffer [Any ] val blockIntervalTimer= new RecurringTimer ( clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator" ) val queueSize=conf.getInt( "spark.streaming.blockQueueSize" ,10 ) val blocksForPushing= new ArrayBlockingQueue [Block ](queueSize) val blockPushingThread=new Thread (){ def run } def addData Any )={ waitToPush() synchronized{ currentBuffer+=data } def updateCurrentBuffer Long ){ var newBlock:Block =null synchronized{ val newBlockBuffer=currentBuffer currentBuffer=new ArrayBuffer [Any ] newBlock= new Block (id,newBlockBuffer) blocksForPushing.put(newBlock) } } def keepPushingBlocks while (areBlocksBeingGenerated){ Option (blocksForPushing.poll( waitingTime ) match { case Some (block)=> pushBLock(block) case None => }) } while (!blocksForPushing.isEmpty){ val block=blocksForPushing.take() pushBlock(block) } } } }
3.1.1.4.1. 保存 class ReceiverSupervisorImpl def pushAndReportBlock val blockStoreResult = **receivedBlockHandler.storeBlock**( blockId, receivedBlock ) } }
3.1.1.4.2. 推送 class ReceiverSupervisorImpl def pushAndReportBlock val blockStoreResult = receivedBlockHandler.**storeBlock**( blockId, receivedBlock ) val blockInfo = ReceivedBlockInfo ( streamId, numRecords, metadataOption, blockStoreResult ) trackerEndpoint.askSync[Boolean ](AddBlock (blockInfo)) } }
3.1.2. bytes格式数据 class ReceiverSupervisorImpl def pushBytes bytes: ByteBuffer , metadataOption: Option [Any ], blockIdOption: Option [StreamBlockId ] ) { pushAndReportBlock( ByteBufferBlock (bytes), metadataOption, blockIdOption ) } }
3.1.3. iterator格式数据 class ReceiverSupervisorImpl def pushIterator iterator: Iterator [_], metadataOption: Option [Any ], blockIdOption: Option [StreamBlockId ] ) { pushAndReportBlock(IteratorBlock (iterator), metadataOption, blockIdOption) } }
3.1.4. ByteBuffer格式数据 class ReceiverSupervisorImpl def pushArrayBuffer arrayBuffer: ArrayBuffer [_], metadataOption: Option [Any ], blockIdOption: Option [StreamBlockId ] ) { pushAndReportBlock(ArrayBufferBlock (arrayBuffer), metadataOption, blockIdOption) } }
3.2. 存储方式
ReceivedBlockHandler 有两个具体的存储策略的实现:
(a) BlockManagerBasedBlockHandler,是直接存到 executor 的内存或硬盘
(b) WriteAheadLogBasedBlockHandler,是先写 WAL,再存储到 executor 的内存或硬盘
3.2.1. BlockManager 将数据存储交给blockManager进行管理,调用blockmanager的putIterator方法,由其实现在不同excutor上的复制以及缓存策略。
class BlockManagerBasedBlockHandler ( blockManager:BlockManager , storageLevel:StorageLevel extends ReceivedBlockHandler def storeBlock var numRecords:Option [Long ]=None val putSucceeded:Boolean = block match { case ArrayBufferBlock (arrayBuffer)=> numRecords=Some (arrayBuffer.size) blockManager.putIterator( blockId, arrayBuffer.iterator, storageLevel, tellMaster=true ) case IteratorBlock (iterator)=> val countIterator= new CountingIterator (iterator) val putResult= **blockManager.putIterato**r( blockId, arrayBuffer.iterator, storageLevel, tellMaster=true ) numRecords=countIterator.count putResult case ByteBufferBlock (byteBuffer)=> blockManager.putBytes( blockId, new ChunkedBytedBuffer ( byteBuffer.duplicate(), storageLevel, tellMaster=true ) ) BlockManagerBasedStoreResult ( blockId, numRecords ) } } }
3.2.2. WAL WriteAheadLogBasedBlockHandler 的实现则是同时写到可靠存储的 WAL 中和 executor 的 BlockManager 中;在两者都写完成后,再上报块数据的 meta 信息 。
BlockManager 中的块数据是计算时首选使用的,只有在 executor 失效时,才去 WAL 中读取写入过的数据 。
同其它系统的 WAL 一样,数据是完全顺序地写入 WAL 的;在稍后上报块数据的 meta 信息,就额外包含了块数据所在的 WAL 的路径,及在 WAL 文件内的偏移地址和长度。
class WriteAheadLogBasedBlockHandler ( blockManager: BlockManager , serializerManager: SerializerManager , streamId: Int , storageLevel: StorageLevel , conf: SparkConf , hadoopConf: Configuration , checkpointDir: String , clock: Clock = new SystemClock extends ReceivedBlockHandler blockStoreTimeout = conf.getInt( "spark.streaming.receiver. blockStoreTimeout" ,30 ).seconds val writeAheadLog=WriteAheadLogUtils . creatLogForReceiver( conf, checkpointDirToLogDir( checkpointDir, streamId, hadoopConf ) ) def storeBlock val serializedBlock = block match {...} val storeInBlockManagerFuture=Future { blockManger.putBytes(...serializedBlock) } val storeInWriteAheadLogFuture=Future { writeAheadLog.write(...serializedBlock) } val combineFuture= storeInBlockManagerFuture.zip( storeInWriteAHeadLogFuture ).map(_._2) val walRecordHandle=ThreadUtils . awaitUtils.awaitResult( combineFuture,blockStoreTimeout ) WriteAheandLogBasedStoreResult ( blockId, numRecords, walRecordHandle ) } }
4. 数据上报 每次成块在 executor 存储完毕后,ReceiverSupervisor 就会及时上报块数据的 meta 信息给 driver 端的 ReceiverTracker;这里的 meta 信息包括数据的标识 id,数据的位置,数据的条数,数据的大小等信息
ReceiverSupervisor会将数据的标识ID,数据的位置,数据的条数,数据的大小等信息上报给driver
class ReceiverSupervisorImpl def pushAndReportBlock val blockStoreResult = receivedBlockHandler.storeBlock( blockId, receivedBlock ) val blockInfo = ReceivedBlockInfo ( **streamId,** **numRecords,** **metadataOption,** **blockStoreResult** ) trackerEndpoint.askSync[Boolean ](AddBlock (blockInfo)) } }
4.1. wal上报 // 报告给driver的信息:blockId,block数量,walRecordHandle
WriteAheandLogBasedStoreResult ( blockId, numRecords, **walRecordHandle** )
4.2. BlockManager上报 // 报告给driver的信息:id和num
BlockManagerBasedStoreResult ( blockId, numRecords )
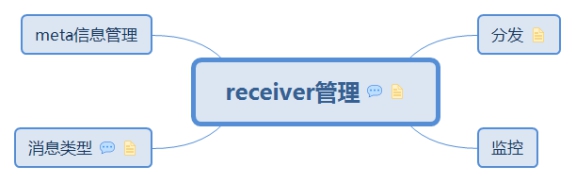
5. receiver管理
分发和监控receiver
作为RpcEndpoint和reciever通信,接收和发送消息
管理上报的meta信息
一方面 Receiver 将通过 AddBlock 消息上报 meta 信息给 ReceiverTracker,另一方面 JobGenerator 将在每个 batch 开始时要求 ReceiverTracker 将已上报的块信息进行 batch 划分,ReceiverTracker 完成了块数据的 meta 信息管理工作。
具体的,ReceiverTracker 有一个成员 ReceivedBlockTracker,专门负责已上报的块数据 meta 信息管理。
5.1. 分发 在 ssc.start() 时,将隐含地调用 ReceiverTracker.start();而 ReceiverTracker.start() 最重要的任务就是调用自己的 launchReceivers() 方法将 Receiver 分发到多个 executor 上去。然后在每个 executor 上,由 ReceiverSupervisor 来分别启动一个 Receiver 接收数据
而且在 1.5.0 版本以来引入了 ReceiverSchedulingPolicy ,是在 Spark Streaming 层面添加对 Receiver 的分发目的地的计算,相对于之前版本依赖 Spark Core 的 TaskScheduler 进行通用分发,新的 ReceiverSchedulingPolicy 会对 Streaming 应用的更好的语义理解,也能计算出更好的分发策略。
并且还通过每个 Receiver 对应 1 个 Job 的方式,保证了 Receiver 的多次分发,和失效后的重启、永活
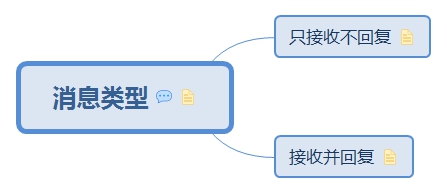
5.2. 监控 5.3. 消息类型
ReceiverTracker :
RpcEndPoint 可以理解为 RPC 的 server 端,底层由netty提供通信支持,供 client 调用。
ReceiverTracker 作为 RpcEndPoint 的地址 —— 即 driver 的地址 —— 是公开的,可供 Receiver 连接;如果某个 Receiver 连接成功,那么 ReceiverTracker 也就持有了这个 Receiver 的 RpcEndPoint。这样一来,通过发送消息,就可以实现双向通信。
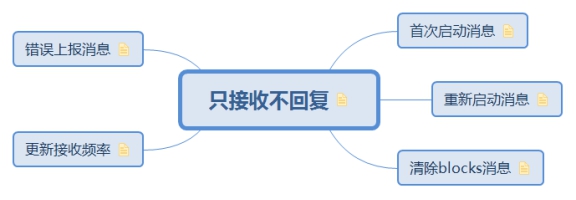
5.3.1. 只接收不回复
只接收消息不回复,除了错误上报消息是excutor发送的以外,其余都是driver的tracker自己给自己发送的命令,接收消息均在ReceiverTracker.receive方法中实现
class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => ... case RestartReceiver => ... case CleanupOldBlocks => ... case UpdateReceiverRateLimit => ... case ReportError => ... } }
5.3.1.1. 首次启动消息 在 ReceiverTracker 刚启动时,发给自己这个消息,触发具体的 schedulingPolicy 计算,和后续分发
class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => val scheduledLocations = schedulingPolicy. scheduleReceivers( receivers, getExecutors ) for (receiver <- receivers) { val executors = scheduledLocations( receiver. streamId ) updateReceiverScheduledExecutors( receiver. streamId, executors ) receiverPreferredLocations( receiver.streamId) = receiver.preferredLocation startReceiver(receiver, executors) } case RestartReceiver => ... case CleanupOldBlocks => ... case UpdateReceiverRateLimit => ... case ReportError => ... } }
5.3.1.2. 重新启动消息 当初始分发的 executor 不对,或者 Receiver 失效等情况出现,发给自己这个消息,触发 Receiver 重新分发
class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => ... case RestartReceiver (receiver)=> val oldScheduledExecutors = getStoredScheduledExecutors( receiver.streamId ) val scheduledLocations = if (oldScheduledExecutors.nonEmpty) { oldScheduledExecutors } else { schedulingPolicy.rescheduleReceiver() startReceiver( receiver, scheduledLocations) case CleanupOldBlocks => ... case UpdateReceiverRateLimit => ... case ReportError => ... } }
5.3.1.3. 清除blocks消息 当块数据已完成计算不再需要时,发给自己这个消息,将给所有的 Receiver 转发此 CleanupOldBlocks 消息
class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => ... case RestartReceiver => ... case CleanupOldBlocks => receiverTrackingInfos.values.flatMap( _.endpoint ).foreach( _.send(c) ) case UpdateReceiverRateLimit => ... case ReportError => ... } }
5.3.1.4. 更新接收频率 ReceiverTracker 动态计算出某个 Receiver 新的 rate limit,将给具体的 Receiver 发送 UpdateRateLimit 消息
class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => ... case RestartReceiver => ... case CleanupOldBlocks => ... case UpdateReceiverRateLimit => ... for (info <- receiverTrackingInfos.get(streamUID); eP <- info.endpoint) { eP.send(UpdateRateLimit (newRate)) } case ReportError => ... } }
5.3.1.5. 错误上报消息 class ReceiverTracker def receive PartialFunction [Any ,Unit ]={ case StartAllReceivers => ... case RestartReceiver => ... case CleanupOldBlocks => ... case UpdateReceiverRateLimit => ... case ReportError => reportError(streamId, message, error) } }
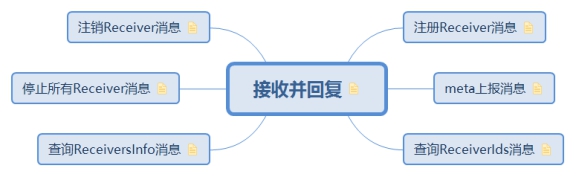
5.3.2. 接收并回复
接收executor的消息,处理完毕后并回复给executor
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => ... case DeregisterReceiver () => ... case AllReceiverIds => ... case StopAllReceivers => ... } }
5.3.2.1. 注册Receiver消息 由 Receiver 在试图启动的过程中发来,将回复允许启动,或不允许启动
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => val successful=registerReceiver( streamId, type , host , executorId , receiverEndpoint , context .senderAddress ) context .reply (successful ) case AddBlock (=> ... case DeregisterReceiver (=> ... case AllReceiverIds => ... case GetAllReceiverInfo => ... case StopAllReceivers => ... } }
具体的块数据 meta 上报消息,由 Receiver 发来,将返回成功或失败
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => context.reply( addBlock(receivedBlockInfo) ) case DeregisterReceiver () => ... case AllReceiverIds => ... case GetAllReceiverInfo => ... case StopAllReceivers => ... } }
5.3.2.3. 查询ReceiverIds消息 executor发送的本地消息。在 ReceiverTracker stop() 的过程中,查询是否还有活跃的 Receiver,返回所有或者的receiverId
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => ... case DeregisterReceiver () => ... case AllReceiverIds => context.reply( receiverTrackingInfos.filter( _._2.state != ReceiverState .INACTIVE ).keys.toSeq ) case GetAllReceiverInfo => ... case StopAllReceivers => ... } }
5.3.2.4. 查询ReceiversInfo消息 查询所有excutors的信息给receiver
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => ... case DeregisterReceiver () => case AllReceiverIds => ... case GetAllReceiverInfo => context.reply( receiverTrackingInfos.toMap ) case StopAllReceivers => ... } }
5.3.2.5. 停止所有Receiver消息 在 ReceiverTracker stop() 的过程刚开始时,要求 stop 所有的 Receiver;将向所有的 Receiver 发送 stop 信息,并返回true
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => ... case DeregisterReceiver () => ... case AllReceiverIds => ... case GetAllReceiverInfo => ... case StopAllReceivers => assert(isTrackerStopping || isTrackerStopped) receiverTrackingInfos.values.flatMap( _.endpoint ).foreach { _.send(StopReceiver ) } context.reply(true ) } }
5.3.2.6. 注销Receiver消息 由 Receiver 发来,停止receiver,处理后,无论如何都返回 true
class ReceiverTracker def receiveAndReply RpcCallContext ){ case RegisterReceiver () => ... case AddBlock () => ... case DeregisterReceiver () => deregisterReceiver( streamId, message, error ) context.reply(true ) case AllReceiverIds => ... case GetAllReceiverInfo => ... case StopAllReceivers => ... } }
addBlock(receivedBlockInfo: ReceivedBlockInfo)方法接收到某个 Receiver 上报上来的块数据 meta 信息,将其加入到 streamIdToUnallocatedBlockQueues 里
class ReceivedBlockTracker val streamIdToUnallocatedBlockQueues = new HashMap [Int , ReceivedBlockQueue ] val writeResult= writeToLog( BlockAdditionEvent ( receivedBlockInfo ) ) if (writeResult){ synchronized{ streamIdToUnallocatedBlockQueues. getOrElseUpdate( streamId, new ReceivedBlockQueue () )+= receivedBlockInfo } } }
5.4.2. batch分配 JobGenerator 在发起新 batch 的计算时,将 streamIdToUnallocatedBlockQueues 的内容,以传入的 batchTime 参数为 key,添加到 timeToAllocatedBlocks 里,并更新 lastAllocatedBatchTime
class ReceivedBlockTracker val timeToAllocatedBlocks = new mutable.HashMap [Time , AllocatedBlocks :Map [ Int , Seq [ReceivedBlockInfo ] ] ] var lastAllocatedBatchTime: Time = null def allocateBlocksToBatch Time ): Unit = synchronized { if (lastAllocatedBatchTime == null || batchTime > lastAllocatedBatchTime) { val streamIdToBlocks = streamIds.map { streamId =>(streamId,getReceivedBlockQueue(streamId) .dequeueAll(x => true )) }.toMap val allocatedBlocks =AllocatedBlocks (streamIdToBlocks) if (writeToLog(BatchAllocationEvent (batchTime, allocatedBlocks))) { timeToAllocatedBlocks.put( batchTime, allocatedBlocks) lastAllocatedBatchTime = batchTime } else { logInfo(s"Possibly processed batch $batchTime needs to be processed again in WAL recovery" ) } } }
5.4.3. 计算DAG生成 JobGenerator 在发起新 batch 的计算时,由 DStreamGraph 生成 RDD DAG 实例时,调用getBlocksOfBatch(batchTime: Time)查 timeToAllocatedBlocks,获得划入本 batch 的块数据元信息,由此生成处理对应块数据的 RDD
class ReceivedBlockTracker def getBlocksOfBatch Time ): Map [Int , Seq [ReceivedBlockInfo ]] = synchronized { timeToAllocatedBlocks.get(batchTime).map { _.streamIdToAllocatedBlocks }.getOrElse(Map .empty) } }
当一个 batch 已经计算完成、可以把已追踪的块数据的 meta 信息清理掉时调用,将通过job清理 timeToAllocatedBlocks 表里对应 cleanupThreshTime 之前的所有 batch 块数据 meta 信息
class ReceivedBlockTracker def cleanupOldBatches Time , waitForCompletion: Boolean ): Unit = synchronized {val timesToCleanup = timeToAllocatedBlocks.keys. filter { _ < cleanupThreshTime }.toSeq} if (writeToLog( BatchCleanupEvent (timesToCleanup))) { timeToAllocatedBlocks --= timesToCleanup writeAheadLogOption.foreach( _.clean( cleanupThreshTime.milliseconds, waitForCompletion) ) } }
脑图制作参考:https://github.com/lw-lin/CoolplaySpark
完整脑图链接地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png