Shuffle Map的过程,即Shuffle Stage的ShuffleTask按照一定的规则将数据写到相应的文件中,并把写的文件”位置信息” 以MapOutput返回给DAGScheduler ,MapOutput将它更新到特定位置就完成了整个Shuffle Map过程.
在Spark中,Shuffle reduce过程抽象化为ShuffledRDD,即这个RDD的compute方法计算每一个分片即每一个reduce的数据是通过拉取ShuffleMap输出的文件并返回Iterator来实现的
1. 对比MapReduce

1.1. 宏观比较
两者差别不大,度分为map和reduce两个阶段。
从 high-level 的角度来看,两者并没有大的差别。 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
1.2. 微观比较
差别较大,Hadoop在Map和reduce阶段都有排序操作,而spark默认使用hash进行聚合,不会提前进行排序操作。
从 low-level 的角度来看,两者差别不小。 Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。目前的 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey() 的操作
1.3. 实现方式
mapreduce将处理流程进行细化出map,shuffle,sort,reduce等几个阶段,而spark只有一个stage和一系列的transformation()
Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。
2. Map
为了分析方便,假定每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
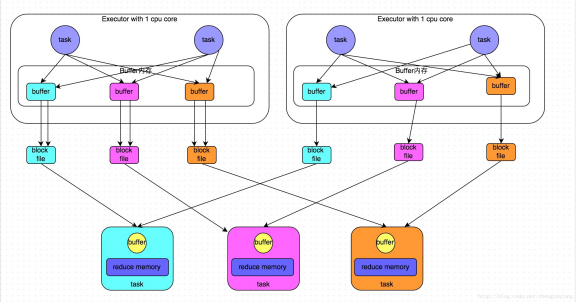
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。参见下面HashShuffleManager图示。
2.1. MapStatus的注册和获取
参见: ShuffleMapStage
MapOutputTracker :是为MapOutput提供一个访问入口,提供了注册和获取MapStatus的接口。
MapOutputTracker可以把每个Map输出的MapStatus注册到Tracker,同时Tracker也提供了访问接口,可以从该Tracker中读取指定每个ShuffleID所对应的map输出的位置;
同时MapOutputTracker也是主从结构,其中Master提供了将Map输出注册到Tracker的入口, slave运行在每个Executor上,提供读取入口, 但是这个读取过程需要和Master进行交互,将指定的 ShuffleID所对应的MapStatus信息从Master中fetch过来;
2.1.1. MapOutputTrackerMaster
参见: 提交stage
driver端,记录shuffle信息
MapStatus数据记录的格式:{shuffleId,mapId,MapStatus}
每个Shuffle都对应一个ShuffleID,该ShuffleID下面对应多个MapID,每个MapID都会输出一个MapStatus,通过该MapStatus,可以定位每个 MapID所对应的ShuffleMapTask运行过程中所对应的机器
通过shuffleID进行索引,存储了所有注册到tracker的Shuffle, 通过registerShuffle可以进行注册Shuffle, 通过registerMapOutput可以在每次ShuffleMapTask结束以后,将Map的输出注册到Track中; 同时提供了getSerializedMapOutputStatuses接口 将一个Shuffle所有的MapStatus进行序列化并进行返回;
class MapOutputTrackerMaster{ |
2.1.2. MapOutputTrackerWorker
excutor端获取shuffle信息,注意:local模式下是直接从trackerMaster获取信息的(worker和master拥有相同的父类,local模式下直接获取不用再走RPC调用)
MapOutputTrackerWorker的实现很简单,核心功能就是getServerStatuses, 它获取指定Shuffle的每个reduce所对应的MapStatus信息
class MapOutputWorker{ |
2.2. 写数据
ShuffleMapTask负责写数据操作,最后会生成.data和.index文件,在执行完毕后返回一个MapStatus对象。
ShuffleMapTask在excutor上获取到具体的writer后进行实际的写操作
class ShuffleMapTask extends Task( |
2.2.1. writer
参见: writer
Get a writer for a given partition. Called on executors by map tasks.
因为Shuffle过程中需要将Map结果数据输出到文件,所以需要通过注册一个ShuffleHandle来获取到一个ShuffleWriter对象,通过它来控制Map阶段记录数据输出的行为。其中,ShuffleHandle包含了如下基本信息:
shuffleId:标识Shuffle过程的唯一ID
numMaps:RDD对应的Partitioner指定的Partition的个数,也就是ShuffleMapTask输出的Partition个数
dependency:RDD对应的依赖ShuffleDependency
class SortShuffleManager{ |
2.2.1.1. BypassMergeSortShuffleWriter
- 按照hash方式排序
- 每个partition产生一个file,然后将相同task产生的文件进行合并。blocks的偏移量被单独存放在一个索引文件中
- 通过IndexShuffleBlockResolver对写入的数据进行缓存
- 使用场景:
如果ShuffleDependency中的Serializer,允许对将要输出数据对象进行排序后,再执行序列化写入到文件,则会选择创建一个SerializedShuffleHandle,生成一个UnsafeShuffleWriter
2.2.1.3. SortShuffleWriter
除了上面两种ShuffleHandle以后,其他情况都会创建一个BaseShuffleHandle对象,它会以反序列化的格式处理Shuffle输出数据。
数据记录格式:
// shuffle_shuffleId_mapId_reducId |
2.2.1.3.1. 写文件
2.2.1.3.1.1. 数据格式
数据格式有两种,如果不需要合并则使用buffer,如果需要合并使用map
class ExternalSorter{ |
2.2.1.3.1.1.1. map
在Map阶段会执行Combine操作,在Map阶段进行Combine操作能够降低Map阶段数据记录的总数,从而降低Shuffle过程中数据的跨网络拷贝传输。这时,RDD对应的ShuffleDependency需要设置一个Aggregator用来执行Combine操作
map是内存数据结构,最重要的是update函数和map的changeValue方法(这里的map对应的实现类是PartitionedAppendOnlyMap)。update函数所做的工作,其实就是对createCombiner和mergeValue这两个函数的使用,第一次遇到一个Key调用createCombiner函数处理,非首次遇到同一个Key对应新的Value调用mergeValue函数进行合并处理。map的changeValue方法主要是将Key和Value在map中存储或者进行修改(对出现的同一个Key的多个Value进行合并,并将合并后的新Value替换旧Value)。
PartitionedAppendOnlyMap是一个经过优化的哈希表,它支持向map中追加数据,以及修改Key对应的Value,但是不支持删除某个Key及其对应的Value。它能够支持的存储容量是0.7 * 2 ^ 29 = 375809638。当达到指定存储容量或者指定限制,就会将map中记录数据Spill到磁盘文件,这个过程和前面的类似
class ExternalSorter{ |
2.2.1.3.1.1.2. buffer
map端不需要排序时使用的数据存储格式
Map阶段不进行Combine操作,在内存中缓存记录数据会使用PartitionedPairBuffer这种数据结构来缓存、排序记录数据,它是一个Append-only Buffer,仅支持向Buffer中追加数据键值对记录
- buffer大小:默认64,最大2 ^ 30 - 1
2.2.1.3.1.2. spill
组装完数据后写磁盘
class ExternalSorter{ |
2.2.1.3.2. 建索引
2.2.2. 写顺序
3. reduce
shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task为下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果
3.1. 读数据
3.2. reduce端获取
参见: ResultTask
调用ShuffleManager通过getReader方法获取具体的Reader,去读数据。
class ShuffledRDD { |
4. shuffle管理入口
ShuffleManager是shuffle整个过程的管理入口,对外提供读写等接口。
ShuffleManager在driver中创建,driver用ShuffleManager进行注册shuffle,执行读写操作等
对Shuffle做了什么优化来提供Spark的性能,本质上就是对ShuffleManager进行优化和提供新的实现
spark2.2.0中已取消对HashShuffleManager的支持
新增了tungsten-sort。
ShuffleManager有两种实现HashShuffleManager和SorShuffleManager,1.1一会的版本默认是SortShuffleManger,可通过
conf.get(“spark.shuffle.manager”, “sort”) 修改默认的shuffle实现方式
SortShuffleManager和HashShuffleManager有一个本质的差别,即同一个map的多个reduce的数据都写入到同一个文件中;那么SortShuffleManager产生的Shuffle 文件个数为2*Map个数
// shuffleManger提供的功能 |
4.1. HashShuffleManager
spark2.2.0中已取消对HashShuffleManager的支持
(SPARK-14667)。参考:http://lxw1234.com/archives/2016/05/666.htm
HashShuffleManager是Spark最早版本的ShuffleManager,该ShuffleManager的严重缺点是会产生太多小文件,特别是reduce个数很多时候,存在很大的性能瓶颈。
最初版本:ShuffleMapTask个数×reduce个数
后期版本:
并发的ShuffleMapTask的个数为M
xreduce个数
4.2. SortShuffleManager

参考:http://shiyanjun.cn/archives/1655.html
4.2.1. reader
4.2.1.1. BlockStoreShuffleReader
根据partition的起止位置,从别的节点获取blockURL,node信息组成reader,
class BlockStoreShuffleReader[K, C]( |
4.2.2. writer
参见: writer
Shuffle过程中需要将Map结果数据输出到文件,所以需要通过注册一个ShuffleHandle来获取到一个ShuffleWriter对象,通过它来控制Map阶段记录数据输出的行为

