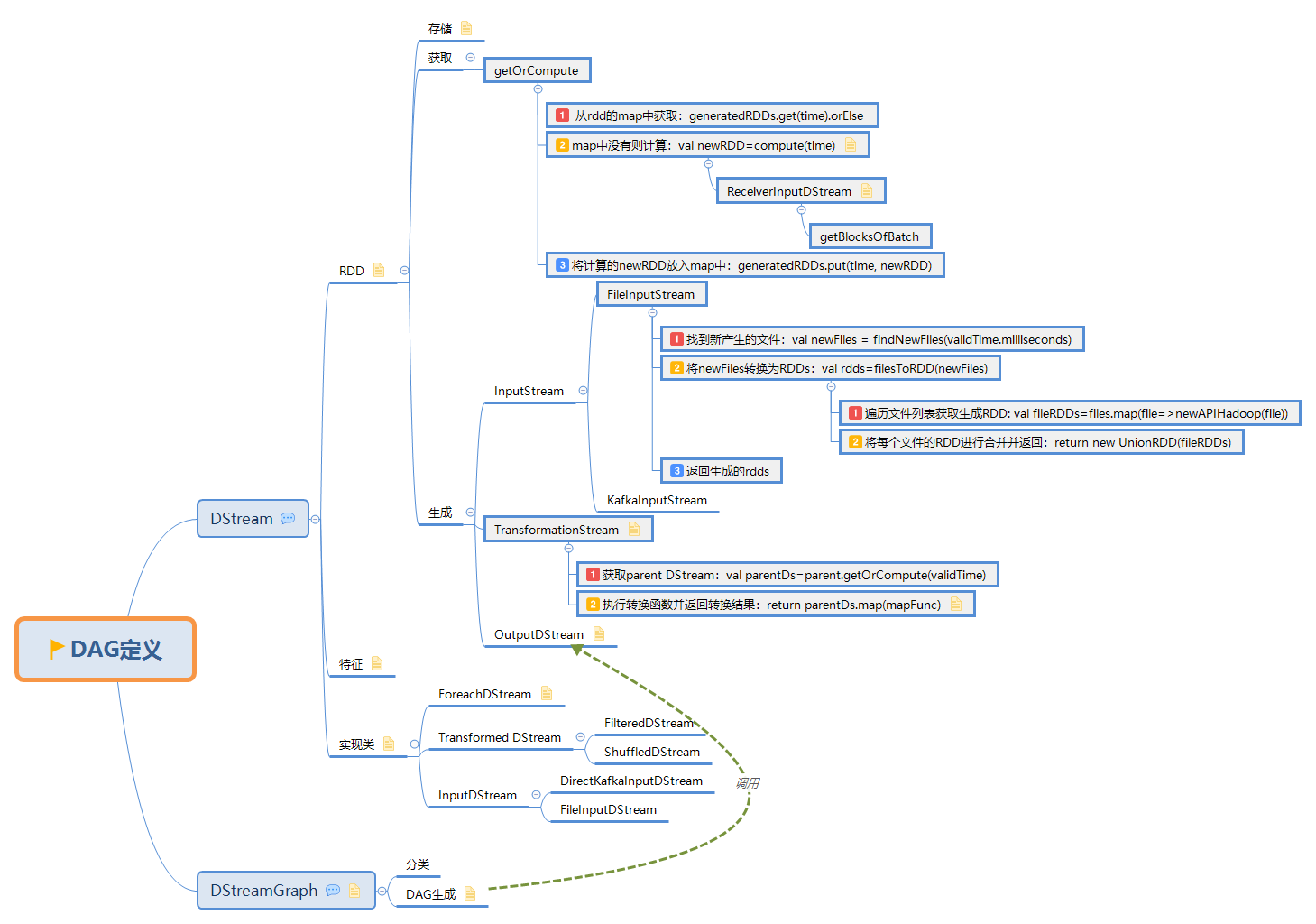
此文是从思维导图中导出稍作调整后生成的,思维脑图对代码浏览支持不是很好,为了更好阅读体验,文中涉及到的源码都是删除掉不必要的代码后的伪代码,如需获取更好阅读体验可下载脑图配合阅读:
此博文共分为四个部分:




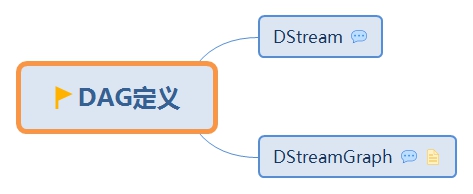
1. DStream
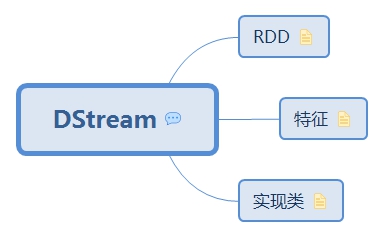
1.1. RDD
DStream和RDD关系:
DStream is a continuous sequence of RDDs: |
1.1.1. 存储
存储格式
DStream内部通过一个HashMap的变量generatedRDD来记录生成的RDD:
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] () |
其中 :
- key: time是生成当前batch的时间戳
- value: 生成的RDD实例
每一个不同的 DStream 实例,都有一个自己的 generatedRDD,即每个转换操作的结果都会保留
1.1.2. 获取
1.1.2.1. getOrCompute

从rdd的map中获取:generatedRDDs.get(time).orElse
map中没有则计算:val newRDD=compute(time)
将计算的newRDD放入map中:generatedRDDs.put(time, newRDD)
其中compute方法有以下特点:
不同DStream的计算方式不同
inputStream会对接对应数据源的API
transformStream会从父依赖中去获取RDD并进行转换得新的DStream
compute方法实现:
class ReceiverInputDStream{ |
1.1.3. 生成
RDD主要分为以下三个过程:InputStream -> TransFormationStream -> OutputStream
1.1.3.1. InputStream
inputstream包括FileInputStream,KafkaInputStream等等
1.1.3.1.1. FileInputStream
FileInputStream的生成步骤:

找到新产生的文件:val newFiles = findNewFiles(validTime.milliseconds)
将newFiles转换为RDDs:val rdds=filesToRDD(newFiles)
2.1. 遍历文件列表获取生成RDD: val fileRDDs=files.map(file=>newAPIHadoop(file))
2.2. 将每个文件的RDD进行合并并返回:return new UnionRDD(fileRDDs)
返回生成的rdds
1.1.3.2. TransformationStream

RDD的转换实现:
- 获取parent DStream:val parentDs=parent.getOrCompute(validTime)
- 执行转换函数并返回转换结果:return parentDs.map(mapFunc)
转换类的DStream实现特点:
传入parent DStream和转换函数
compute方法中从parent DStream中获取DStream并对其作用转换函数
private[streaming]
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[U]] = {
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}
}
不同DStream的getOrCompute方法实现:
- FilteredDStream:
parent.getOrCompute(validTime).map(_.filter(filterFunc) - FlatMapValuedDStream:
parent.getOrCompute(validTime).map(_.flatMapValues[U](flatMapValueFunc) - MappedDStream:
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
在最开始, DStream 的 transformation 的 API 设计与 RDD 的 transformation 设计保持了一致,就使得,每一个 dStreamA.transformation() 得到的新 dStreamB 能将 dStreamA.transformation() 操作完美复制为每个 batch 的 rddA.transformation() 操作。这也就是 DStream 能够作为 RDD 模板,在每个 batch 里实例化 RDD 的根本原因。
1.1.3.3. OutputDStream
OutputDStream的操作最后都转换到ForEachDStream(),ForeachDStream中会生成Job并返回。
伪代码
def generateJob(time:Time){ |
源码
private[streaming] |
通过对output stream节点进行遍历,就可以得到所有上游依赖的DStream,直至找到没有父依赖的inputStream。
1.2. 特征
DStream基本属性:
父依赖: dependencies: List[DStream[_]]
时间间隔:slideDuration:Duration
生成RDD的函数:compute
1.3. 实现类
DStream的实现类可分为三种:输入,转换和输出
DStream之间的转换类似于RDD之间的转换,对于wordCount的例子,实现代码:
val lines=ssc.socketTextStream(ip,port) |
每个函数的返回对象用具体实现代替:
val lines=new SocketInputDStream(ip,port) |
1.3.1. ForeachDStream
DStream的实现分为两种,transformation和output
不同的转换操作有其对应的DStream实现,所有的output操作只对应于ForeachDStream
1.3.2. Transformed DStream
1.3.3. InputDStream
2. DStreamGraph
2.1 DAG分类
逻辑DAG: 通过transformation操作正向生成
物理DAG: 惰性求值的原因,在遇到output操作时根据dependency逆向宽度优先遍历求值。
2.2 DAG生成
DStreamGraph属性
inputStreams=new ArrayBuffer[InputDStream[_]]() |
DAG实现过程
通过对output stream节点进行遍历,就可以得到所有上游依赖的DStream,直至找到没有父依赖的inputStream。
sparkStreaming 记录整个DStream DAG的方式就是通过一个DStreamGraph 实例记录了到所有output stream节点的引用
generateJobs
def generateJobs(time: Time): Seq[Job] = { |
脑图制作参考:https://github.com/lw-lin/CoolplaySpark
完整脑图链接地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png

